I thought I’d take a look at Blackhat trainings and see if there was anything cheap I could pick up. Sadly, each course has it’s own subpage and the prices are behind that link. A budget conscious attendee would have to click a WHOLE lotta links to see what’s cheap and what isn’t. Looks like a chance to practice using Python.
This is a basic scraper that uses XPaths to find it’s content. Definitely try to play with XPaths if you have a chance. Since it’s a query language like SQL you’ll be able to quickly find information without iterating over everything.
As I’m using the Requests library you’ll need a sudo pip install requests before it’ll work.
First we grab the page with the list of courses, convert it to a tree structure, and search for the page links.

Now how do we chose the right xpath for this? You’ll want to find a path that locates ONLY what we’re looking for, usually the class names will narrow in on exactly what you want.
 In this case, every course has a div containing an
In this case, every course has a div containing an <h2> that is a parent to the href we seek.
It’s helpful to use the console and the $x() (shortcut for document.evaluate()) function to incrementally work out the syntax. Start broad and narrow it down.
![Browser javascript console showing: $x('//div[contains(@class,"course-description")]') and it's array results](/images/xpathinspect2.png)
From there we just loop through the results, save the title and the link, download those and repeat the same thing to find the prices for each course.
Here’s how to sort by price. Notice the 20 cheapest courses…
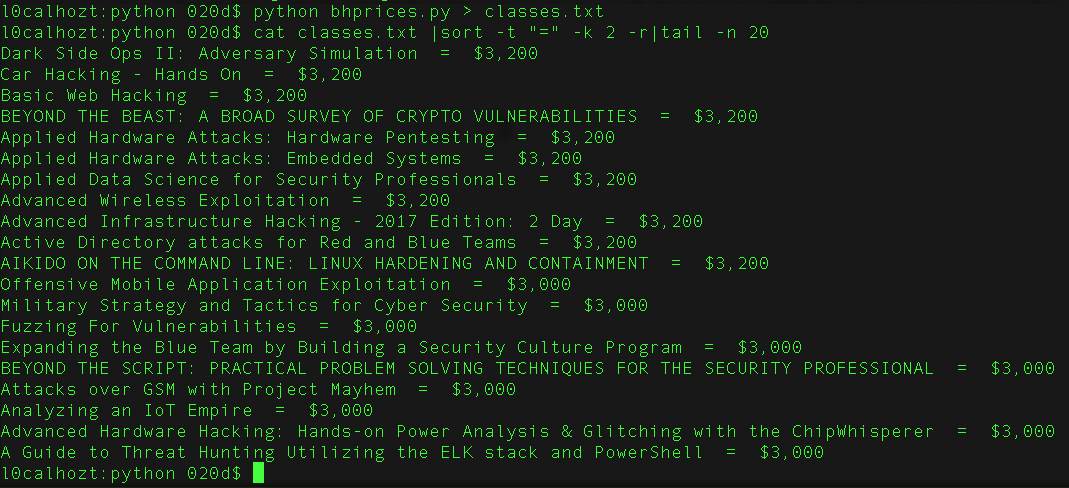
Oh well… defcon is more fun anyways. :p
Code posted at:Github